-
파이썬 웹 스크레이핑 기초마케팅/파이썬 2023. 6. 5. 17:23
1. 웹 스크레이핑이란?
컴퓨터 소프트웨어 기술을 활용하여 웹 사이트 내의 정보를 자동으로 추출하는 것
1-2. 웹스크레이핑 vs 웹 크롤링 차이점
웹 크롤링은 웹 사이트 전체의 내용을 긁어와서 복제하는 것을 의미하며, 보통 대규모로 이뤄짐.
반면, 웹 스크레이핑은 웹 사이트 내용을 가져와서 특정 데이터를 추출하는 것을 의미함.
2 웹 스크레이핑 과정
주제선정 -> 데이터 보유 웹 사이트 분석 -> 웹 사이트에서 데이터 추출 -> 데이터 처리 -> 데이터 활용
3. 웹사이트 이용 규약
항목 설명 예시 User-agent 대상 웹 크롤링 봇의 이름, *이면 전체 User-agent: Googlebot Disallow 접근을 허용하지 않는 경로 /이면 모든 경로 허용 안함 Disallow: /admin/ Allow 접근을 허용하는 경로. /이면 모든 경로 허용 Allow : /help/ Crawl-delay 접근 주기 제한 시간(단위:초), 한번 접근 후 다음 접근이 제한되는 시간 Crawl-delay: 30 Sitemap 사이트맵 파일의 URL Sitemap: https://www.google.com/
sitemap.xml4. 웹 데이터의 요청과 응답 과정
컴퓨터가 웹 브라우저로 인터넷을 통해 웹사이트에 HTTP 형식으로 원하는 정보를 요청하면, 웹 서버가 HTTP형식으로 응답해 HTML 파일을 보냄. 이 HTML 파일을 컴퓨터의 웹 브라우저가 사람이 알아보기 쉬운 형태로 변환해주면 확인 가능
4-1. HTML 요청을 위한 메서드
GET메서드 서버에 이미 있는 자원(리소스, 데이터)에 대한 조회 요청 POST매서드 서버에 새로운 자원 생성을 요청 PUT매서드 서버에 있는 자원에 대한 수정 요청 DELETE매서드 서버에 있는 자원에 대한 삭제 요청 5. 웹페이지 언어(HTML) 구조
HTML은 크게 머리(head)와 몸통(body)로 구성되어 있음
<!doctype html> <html> <head> <title>이것은 HTML 예제</html> </head> <body> <h1>출간된 책 정보</h1> <p id="book_title">이해가 쏙쏙 되는 파이썬</p><!doctype html> - HTML 문서임을 명시하기 위한 DTD(Document Type Definition)
<> 로 둘러쌓인 부분 - HTML 태그
<태그>-시작태그, 부가적인 정보를 제공하는 속성(Attributes) 지정 가능
</태그>- 끝 태그
시작태그, 끝 태그 안에 포함된 내용 전체 -> 요소(Element)
*HTML의 id와 같은 태그 속성은 웹 페이지에서 특정 데이터를 추출할 때 중요한 정보
6. 웹 페이지의 소스 가져오기
6-1. 웹 브라우저로 웹 페이지 소스 보기
마우스 우클릭 -> [페이지 소스 보기] : HTML 코드 확인 가능

6-2.requests 라이브러리 활용
파이썬으로 웹 페이지의 HTML 파일 소스 가져오기 -> 파이썬 내장 패키지 'urllib'
아나콘다 설치 시 requests 라이브러리 자동 설치
requests 라이브러리 -> HTTP 요청 방법 (GET, POST, PUT DELETE 메서드) 모두 지원
속성 타입 설명 r.status_code 정수형 요청에 대한 응답 코드, 성공 시 200반환 r.url 문자열 요청에 대한 최종 url r.text 문자열 응답 본문의 문자열 데이터 r.content 바이너리 응답 본문의 바이너리(바이트) 데이터 r.json() 딕셔너리 응답 본문을 JSON 형식으로 변환한 데이터 r.headers 딕셔너리 응답 헤더 1) POST 메서드를 지원하는 웹 사이트에서 requests 라이브러리 post()를 이용해 객체를 가져오는 법
응답 객체 r을 가져오기, data와 json은 바디에 저장되어 서버에 전달할 데이터를 지정하며, 둘 중 하나만 사용
import requests r=requests.post(url[,data=None,json=None,headers=None])2) get()이용하여 객체 가져오는법
import requests r=requests.get(url,[,params=None,headers=None])7. GET메서드로 웹사이트 소스 가져오기
1) request.get("웹사이트 주소")
HTML 소스를 위한 응답 객체 반환 -> 접속 성공 시<Response 200> 반환

응답 객체를 이용하여 상태 코드 확인하기 -> r.status_code 사용
2) r.text[] -> 응답 객체에서 가져온 소스 확인
전체를 돌릴 시 많은 양이 출력되므로 범위 설정하여 가져오기
import requests r=requests.get("https://www.google.co.kr") r.text[0:100]
3) r.headers -> 응답 헤더 확인
import requests r=requests.get("https://www.google.co.kr") r.headers
4) 한번에 코드 작성하기-> requests.get("url주소").text
import requests html=requests.get("https://www.google.co.kr").text html[0:100]
8. 웹페이지 소스 분석하고 처리하기
HTML 소스를 요소별로 분류하는 법 -> 파싱(Parsing)
1) Beautiful Soup 라이브러리를 이용하여 HTML 소스 분류하기
from bs4 import BeautifulSoup #test code html="""<html><body><div><span>/ <a href=http://www.naver.com>naver</a>/ <a href=http://www.google.com>google</a>/ <a href=http://www.daum.net>daum</a>/ </span></div></body></html?""" #BeautifulSoup HTML Pasing soup=BeautifulSoup(html,'lxml') soup-> lxml은 HTML 소스를 처리하기 위한 파서(paser)
2) prettify() 메서드를 이용하여 html 구조 확인하기
from bs4 import BeautifulSoup #test code html="""<html><body><div><span>/ <a href=http://www.naver.com>naver</a>/ <a href=http://www.google.com>google</a>/ <a href=http://www.daum.net>daum</a>/ </span></div></body></html?""" #BeautifulSoup HTML Pasing soup=BeautifulSoup(html,'lxml') print(soup.prettify())
-파싱 결과에서(soup) 태그가 있는 요소를 찾기 위해서는 find()나 find all() 사용하여 확인 가능
soup.find("태그") #HTML소스에서 해당 태그가 있는 첫 번째 요소 반환 soup.find_all("태그") #HTML 소스에서 해당 태그가 있는 모드 요소를 찾아 리스트로 반환
html 소스에 첫번째 a태그를 찾아 a태그의 전체 요소 반환 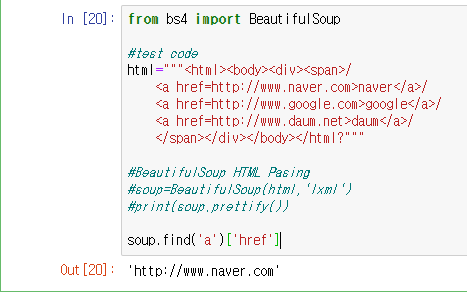
a태그의 요소에서 href속성만 가져오기 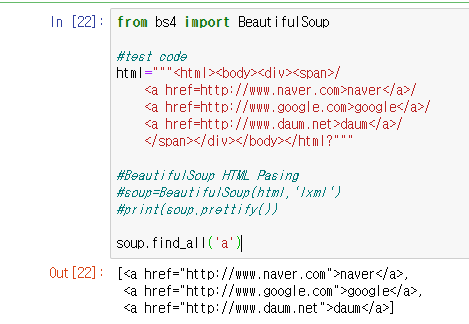
a태그로 시작하는 모든 요소 가져오기 /find_all->리스트 형태 출력 -요소 반환 결과에서 텍스트 문자열만 얻고 싶을 때 -> get.text()
요소반환결과.get_text()
a가 포함된 텍스트만 추출 for문을 이용해 get_text로 html 웹사이트 이름 모두 추출하기
요소 반환 결과의 속성값을 알고 싶을때

요소반환결과['속성'] or 요소반환결과.get('속성')9. 웹 사이트 주소에 부가 정보 추가하기
9-1. 기본 웹사이트 주소 + 하위 경로 변경하기

베이스url에 하위 폴더(event)를 연결하여 하나의 url로 만듬, 기본 주소 변경 없이 하위 경로만 바꿀 때 유용함
request.get()을 이용하여 데이터 요청- 응답받기

10. 웹 사이트 주소에 매개변수 추가하기
물음표(?)를 이용해 해당 웹 사이트에 매개변수를 보낼 수 있음
지정된 키(key)에 값(value)를 넣어 데이터를 요청하기 위한 전체 url을 입력할 수 있음
매개변수가 2개 이상일 때 -> '&'로 연결
ex) 네이버 검색창에 '영양제' 검색어 입력 검색결과 출력 시
https://search.naver.com/search.naver ?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EC%98%81%EC%96%91%EC%A0%9C
예제1) 네이버에 python 검색하여 찾을 매개변수 직접 입력하기
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=python \
방법1. 직접 URL 입력
import requests where_value='nexearch' sm_value='top_hty' fbm_value=1 ie_value='utf8' query_value='python' base_url="https://search.naver.com/search.naver" parameter="?where={0}&sm={1}&fbm={2}&ie={3}&query={4}".format(where_value,sm_value,fbm_value,ie_value,query_value) url_para=base_url+parameter r=requests.get(url_para) print(r.url)
방법2. requerst.get()에 params 옵션 사용하여 딕셔너리와 키값으로 전달
import requests where_value='nexearch' sm_value='top_hty' fbm_value=1 ie_value='utf8' query_value='python' url="https://search.naver.com/sear.naver" parameters={"where":where_value,"sm":sm_value,"fbm":fbm_value,"ie":ie_value,"query":query_value} r=requests.get(url,params=parameters) print(r.url)'마케팅 > 파이썬' 카테고리의 다른 글
파이썬 웹 스크래핑_ 날씨 정보 가져오기 (0) 2023.06.09 파이썬 기초8. 딕셔너리, 집합 (0) 2023.06.01 [파이썬 웹 스크래핑] 페이지 주소 가져오기 (0) 2023.06.01 파이썬 기초7. 함수 (1) 2023.05.30 파이썬 기초6. 리스트(list), remove, append, insert, del, sorted, reverse (0) 2023.05.26